Research
Our lab studies deep learning methods for computer vision and visual intelligence. We aim to build robust perception models that can understand complex visual scenes, learn from limited supervision, and support practical applications in medical imaging, multimodal perception, and adaptive recognition.
Keywords
Few-shot Learning Medical Image Segmentation Semantic Segmentation Pattern Recognition Multimodal Learning Deep Learning Image Processing
Research Areas
Medical Image Analysis
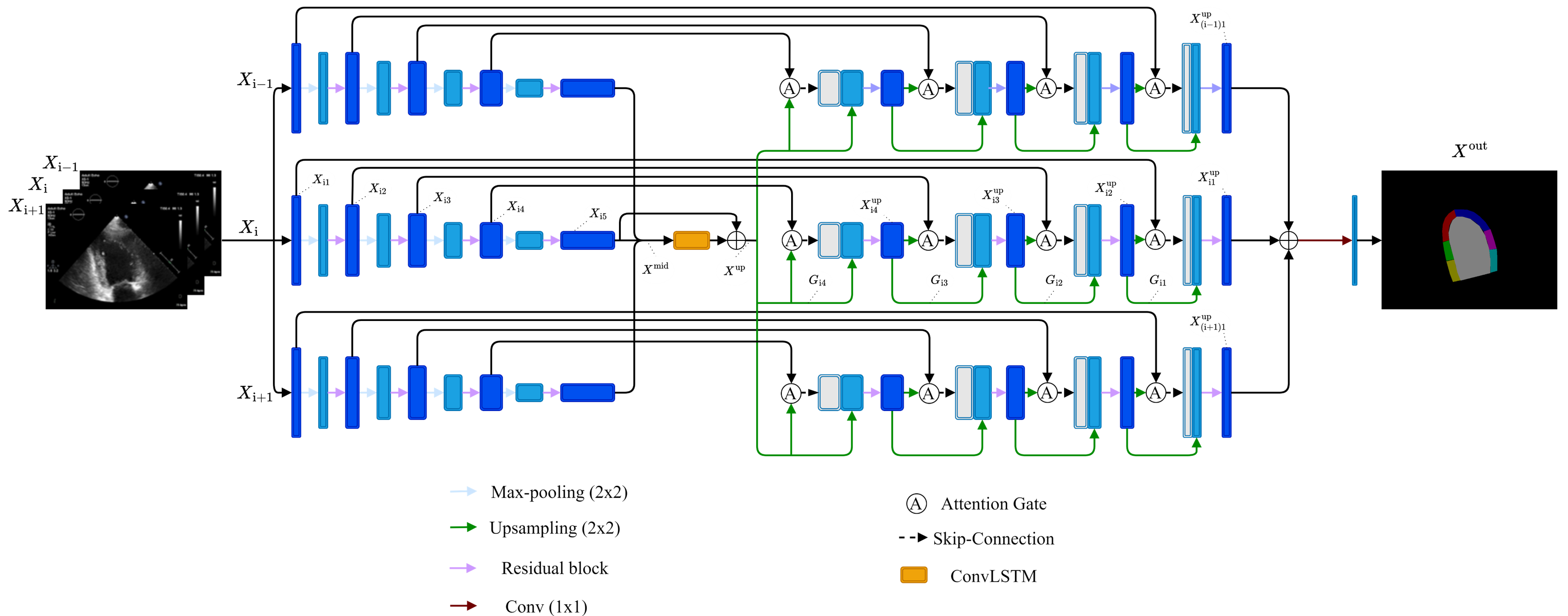
Echocardiographic videos contain important continuity across neighboring frames, not just isolated image information. Spatial and temporal cues are used to support stable medical image segmentation and reduce missed or false detections.
Multimodal Fusion
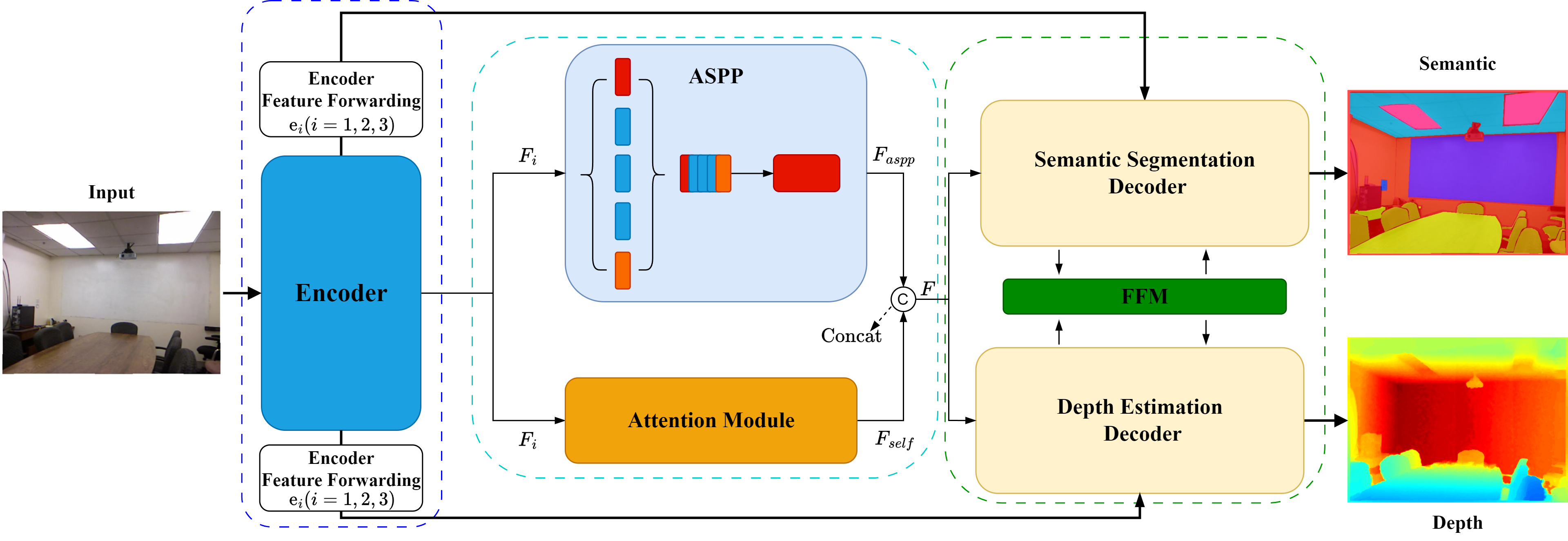
Depth information adds scene structure that is difficult to capture from RGB images alone. Combining appearance and depth cues helps semantic segmentation become more accurate and robust in complex environments.
Few-shot Learning
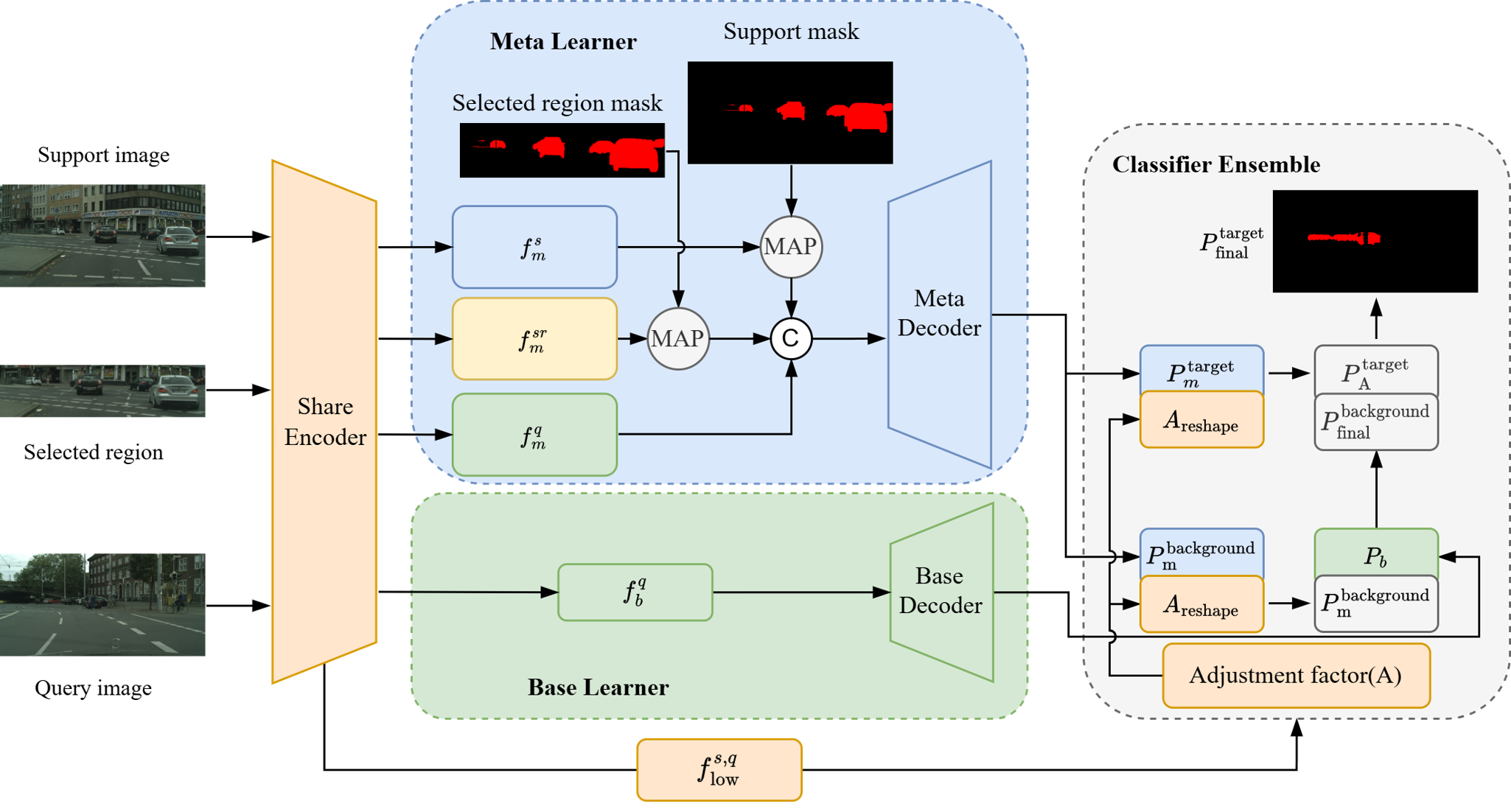
Few-shot semantic segmentation focuses on segmenting unseen categories from only a small number of labeled examples. Reducing background noise and scene differences makes the model easier to adapt when annotation data is limited.